
What is PIV servo control? It typically involves two components: feedforward control, which adds auxiliary velocity and (in some cases) acceleration signals to the servo loop in order to improve command tracking, and either PID or PIV control, which works to maximize the system’s disturbance rejection. The distinction between PID and PIV control is that PID control is based on position error, while PIV control is based on both position error and velocity error.
In a servo system, disturbances are unexpected forces that cannot be modeled in advance. Examples include changes in load inertia or torque variations at the motor shaft.
PID control is a common method of servo tuning and is well-suited for applications that can be modeled as a linear function that does not vary with time . The input of the PID algorithm is an error signal (difference between the commanded position and the achieved position), and the output is simply the sum of three signals: a signal proportional to the error, a signal proportional to the integral of the error, and a signal proportional to the derivative of the error.
What is PIV?
PIV control goes one step further and places a velocity feedback loop inside the position feedback loop. This additional feedback loop makes PIV control better at regulating velocity than PID control is. Typically, the velocity loop uses PI (proportional, integral) control, while the position loop uses P (proportional) control. The velocity correction signal is determined by the position error multiplied by the proportional gain, Kp. The integral gain, Ki, is applied to the velocity error (rather than to the position error, as in the PID controller). The derivative gain, Kd, is replaced by a velocity feedback gain, Kv.
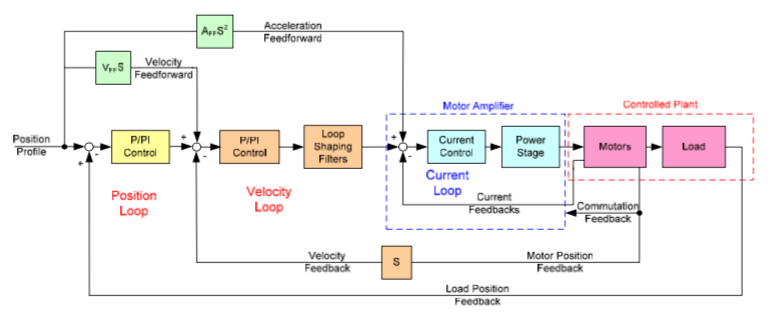
Image credit: ACS Motion Control
Velocity feedback gain, Kv, is similar to derivative gain, Kd. However, where Kd scales the derivative of the position error (that is, the difference between the instantaneous trajectory position and the feedback position), Kv scales only the velocity that is estimated from the feedback device.
Velocity feedback is taken from the motor encoder, while position feedback is commonly taken from a feedback device mounted to the load itself. This dual feedback helps to better compensate for backlash or low stiffness in the system, caused by belts, screws, gears, and other mechanical connections. Note that it’s important to use high-resolution feedback for the velocity estimation, as insufficient resolution can result in velocity ripple.
Tuning for a PIV controller is generally considered to be easier than that of a PID controller. This is because the nested velocity and position loops in the PIV controller make the tuning process mostly non-iterative, where PID controller tuning can take many iterations to achieve the desired command tracking and suitable disturbance rejection.
Leave a Reply
You must be logged in to post a comment.